Introdução ao Machine Learning
Machine Learning (ML) é uma área da inteligência artificial onde criamos algoritmos para ensinar a máquina a desempenhar determinadas tarefas.
Nesse artigo iremos tratar alguns conceitos básicos dessa área a fim de preparar terreno para nossa primeira implementação prática.
Um algoritmo de ML basicamente pega um conjunto de dados de entrada e baseado nos padrões encontrados gera as saídas.
Cada entrada desse conjunto de dados possuem suas features, ter um conjunto delas é o ponto inicial para qualquer algoritmo de ML.
Feature
Feature é uma característica que descreve um objeto.
Qualquer atributo de um objeto pode ser tratado como feature, seja um número, um texto, uma data, um booleano etc.
Como no objeto pessoa, vemos vários atributos que o descreve, esses atributos são suas features
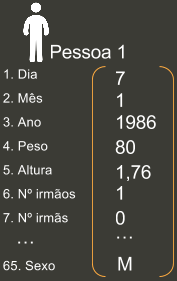
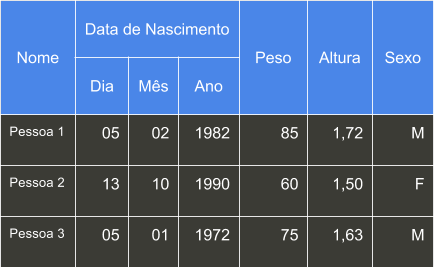
Na tabela abaixo, temos um conjunto maior de dados, onde:
- Cada coluna é uma feature que descreve a linha;
- Cada linha é uma entrada e tem seu conjunto de features.
As features são as entradas dos algoritmos de ML, quanto mais detalhes o algoritmo tiver sobre uma entrada, mais facilmente achará padrões nos dados.
Features ruins podem prejudicar o desempenho do algoritmo. Features boas são a chave para o sucesso de um algoritmo.
Boa parte do trabalho em ML é conseguir trabalhar os dados e gerar boas features em cima deles, o que é conhecido como engenharia de features ou feature engineering.
Existem diversas técnicas para gerar features, seja através do conhecimento da natureza dos dados ou da aplicação de matemática e estatística para criá-las em cima dos dados.
Tendo nossas features em mãos podemos aplicar diversos algoritmos de aprendizado nelas. Existem dois grandes grupos de algoritmos em ML, os de aprendizagem supervisionada e os de aprendizagem não supervisionada.
Aprendizagem supervisionada
Quando você tem um conjunto de entradas que possuem as saídas que deseja prever em outros dados. Com conhecimento das entradas e saídas de um número suficiente de dados, os algoritmos desse grupo podem achar os padrões que relacionam as entradas com as saídas. Dessa forma, se tivermos novos dados apenas com as entradas, podemos prever as saídas com base nesses padrões previamente encontrados.
São divididos em dois grupos: classificação e regressão.
Classificação
Como o próprio nome já diz, é quando queremos prever uma classificação.
Os dados usados no aprendizado possuem essas classificações.
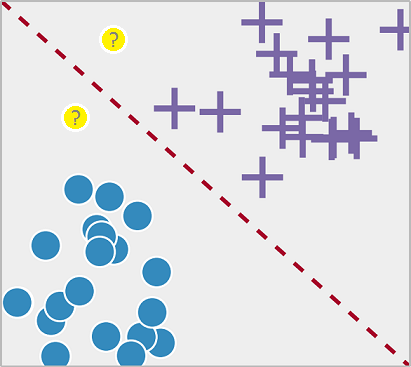 Como vemos na imagem temos dados do tipo bolinha azul e do tipo + lilás, e queremos saber de qual tipo seriam os novos dados (bolinha amarela).
Como vemos na imagem temos dados do tipo bolinha azul e do tipo + lilás, e queremos saber de qual tipo seriam os novos dados (bolinha amarela).
Exemplo: Classificar um e-mail como spam ou não spam.
- Pegaríamos vários e-mails já classificados como spam ou não spam;
- Treinaríamos um algoritmo que seria capaz de encontrar os padrões determinantes para cada uma das classes;
- Teríamos um algoritmo capaz de ler um novo e-mail e classificar como spam ou não baseado em suas características.
Regressão
Quando queremos prever um valor.
Os dados usados no aprendizado possuem esse valor.
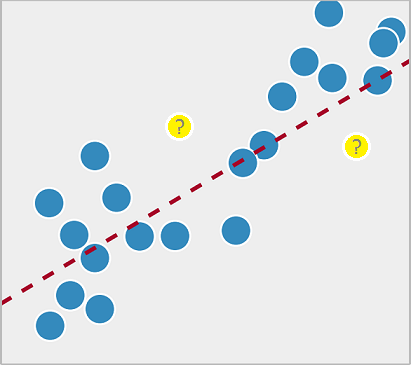 Como vemos na imagem temos dados distribuídos ao redor da linha vermelha, que é valor que desejamos encontrar.
Um novo dado poderia ser colocado ali conforme suas características e dependendo de onde ficaria na linha, encontraríamos o valor desejado.
Como vemos na imagem temos dados distribuídos ao redor da linha vermelha, que é valor que desejamos encontrar.
Um novo dado poderia ser colocado ali conforme suas características e dependendo de onde ficaria na linha, encontraríamos o valor desejado.
Exemplo: Determinar o preço de uma casa.
- Pegaríamos as características de várias casas (bolinhas azuis) e os seus preços (linha vermelha);
- Treinaríamos um algoritmo capaz de criar uma relação entre as características da casa e o seu preço;
- Teríamos um algoritmo capaz de determinar o preço de uma nova casa (bolinhas amarelas) baseado em suas características.
No treinamento de algoritmos de aprendizado supervisionado sempre usamos dados com os valores que desejamos encontrar.
No primeiro exemplo tínhamos vários e-mails rotulados como spam e não spam que foram usados no treinamento.
No segundo exemplo tínhamos várias casas com seus preços que foram usadas nos treinamento.
Aprendizagem não supervisionada
Quando você tem um conjunto de entradas sem as saídas que você deseja. Com base nas características desses dados podemos gerar um agrupamento ou processá-los a fim de gerar novas formas de expressar essas características.
São divididos em dois grupos: redução de dimensionalidade e clusterização.
Redução de dimensionalidade
Consiste em pegar um conjunto de dados de alta dimensão e reduzir para um número menor de dimensões de forma que represente o máximo possível os dados originais. Consideramos a quantidade de features como as dimensões.
No exemplo abaixo temos o objeto pessoa com 65 features, ou seja, 65 dimensões. Passamos isso pelo algoritmo e reduzimos para 2 dimensões. Os complementos 1 e 2 gerados representam o máximo possível as 65 features originais. Como são duas dimensões é possível plotar no plano.
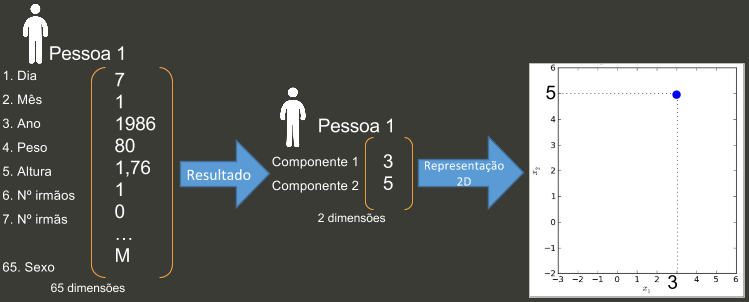
Podemos fazer a mesma redução para várias pessoas diferentes e colocar no mesmo plano, dessa forma conseguimos enxergar melhor a distribuição dos dados.
Caso os dados tenham uma boa representatividade em 2 dimensões, pessoas com mesmas características podem ficar mais próximas nesse tipo de representação, enquanto pessoas muito diferentes ficam mais distantes.
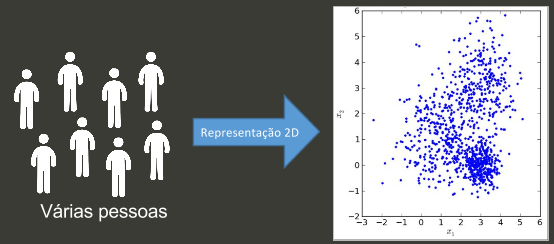
Reduzimos para 2 dimensões para melhor visualização, pois só somos capazes de ver em no máximo 3 dimensões, porém os algoritmos são capazes de lidar com quantas dimensões forem necessárias.
Esse tipo de técnica pode ser usada para facilitar a análise dos dados, como fizemos no exemplo acima.
Também é usado no caso de dados com uma quantidade muito grandes de features, em números muitos elevados podem impedir de alguns tipos de algoritmos funcionarem corretamente, principalmente se o número de features for próximo ou maior do que o número de entradas. Nesse caso, reduzimos as features para um número mais aceitável e então fazemos nosso treinamento normalmente com essas novas features.
Clusterização
Consiste no agrupamento dos dados baseado em suas características, esses grupos são chamados de clusters.
Tomando como partida o exemplo anterior, podemos querer agrupar os dados em 3 grupos, um algoritmo de clusterização seria capaz de analisar os dados e identificar esses grupos baseado nas características desses dados.
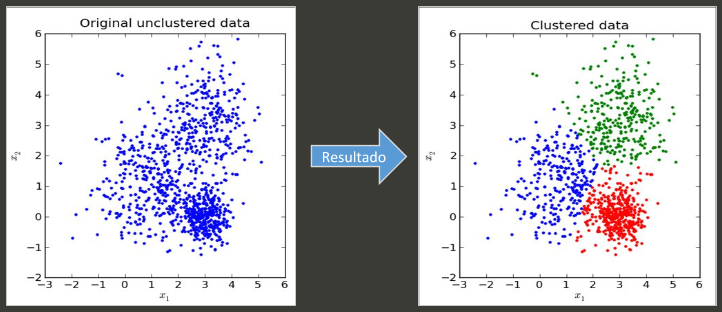
É uma técnica muito poderosa e tem uma aplicabilidade muito alta.
Exemplos:
- Para identificar clientes similares e com isso ser mais assertivo ao oferecer um novo produto;
- Na área médica para agrupar pacientes com os mesmos sintomas;
- Em marketing para segmentação de mercado;
- Para classificação de documentos;
- Para qualquer agrupamento de uma grande de quantidade de dados baseado em suas características.
Aplicação
Existem diversas formas de se aplicar Machine Learning hoje em dia, diferentes linguagens e bibliotecas.
Iremos trabalhar com a linguagem Python e com a biblioteca SciKit Learn ou SkLearn, que é uma poderosa biblioteca focada em Machine Learning para Python.
Atualmente o SkLearn já engloba todos esses grupos de algoritmos que citei.
 No próximo artigo darei exemplos de aplicações práticas usando essa biblioteca.
No próximo artigo darei exemplos de aplicações práticas usando essa biblioteca.
Voltar para página inicial: Carlos Baia