Decision Tree e Random Forest
Nesse artigo vamos fazer nossa primeira implementação prática de um algoritmo de Machine Learning. Pegaremos uma base de dados real, faremos algumas análises nos dados e logo após implementaremos nosso primeiro algoritmo. Usaremos um algoritmo de classificação para atingir nosso objetivo.
Ambiente de desenvolvimento
Antes de desenvolver nosso primeiro código, vamos configurar nosso ambiente de desenvolvimento. A linguagem de programação utilizada será o Python e as principais bibliotecas utilizadas serão:
- Numpy: Biblioteca matemática muito poderosa, facilita muito o trabalho com arrays e tem diversas funções de álgebra, estatística e computação científica no geral. É implementada em C para garantir alto desempenho, o que é muito importante quando se trabalha com uma grande quantidade de dados.
- Pandas: Muito útil para estruturar os dados, ajuda muito na analise e na manipulação de grande quantidade de dados. Também é implementada em C para garantir alto desempenho.
- Matplotlib: Utilizada para plotar gráficos, é uma ótima ferramenta na análise dos dados.
- SciKit Learn ou SkLearn: Possui diversos algoritmos de Machine Learning. Será a principal biblioteca que utilizaremos.
Para desenvolver o código é possível usar sua IDE de preferência, caso não tenha uma, recomendo o uso do Jupyter para as analises iniciais da base e os primeiros testes. Quando a complexidade do código aumentar é só migrar para o PyCharm e continuar a desenvolver.
Não é necessário instalar o Python e todas essas bibliotecas uma a uma, o Anaconda é uma plataforma para data science que já inclui tudo isso. É só instalar e começar a desenvolver. Todas as ferramentas citada funcionam em Windows, Linux e Mac.
Base de dados
Um bom local para encontrar dados para praticar, é o UCI Machine Learning Repository. Lá você encontra base para diversas áreas, algoritmos e tamanhos. A maioria dos problemas são bem detalhados, com referências e detalhes de como foram extraídas as features iniciais.
A base escolhida para o nosso exemplo foi a Iris Data Set.
O problema proposto é através das características fornecidas de uma flor, descobrir de qual das flores abaixo que se trata.

Os dados estão em formato CSV e possui 150 entradas:
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
...
5.1,2.5,3.0,1.1,Iris-versicolor
5.7,2.8,4.1,1.3,Iris-versicolor
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
...Cada uma das entradas possui 5 colunas com a seguinte descrição:
1. sepal length in cm
2. sepal width in cm
3. petal length in cm
4. petal width in cm
5. class:
- Iris Setosa
- Iris Versicolour
- Iris VirginicaPetal (pétala) e sepal (sépala) são partes da flor, são fornecidas as dimensões em centímetros dessas partes e
com isso devemos classificar a flor entre Iris Setosa, Versicolour ou Virginica.

Analisando os dados
Baixe a base de dados nesse link e vamos utilizar o Pandas para carregar os dados.
O Pandas por padrão pega a primeira linha como nome das colunas, porém ao abrir a base vemos que esses nomes não estão presentes nessa base.
Com base na descrição fornecida, vamos passar esses nomes na leitura dos dados.
import pandas as pd
names = ['SepalLength', 'SepalWidth',
'PetalLength', 'PetalWidth',
'Class']
df = pd.read_csv('iris.data', names=names)O objeto df é um DataFrame, nele está os dados carregados e diversas funções muito poderosas para manipular os dados. Recomendo a leitura da documentação para entender tudo que ele pode fazer.
Com os códigos abaixo começamos a ver o tamanho e formato dos dados.
print("Linhas: %d, Colunas: %d" % (len(df), len(df.columns)))Output: Linhas: 150, Colunas: 5
A função head nos mostra por padrão as primeiras 5 linhas do DataFrame. Somos capazes de ver ai o nome de nossas features e a classificação (Class) da flor.
df.head() Output:
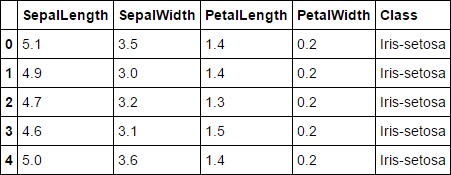
Vamos ver quantas flores de cada categória existe na nossa base.
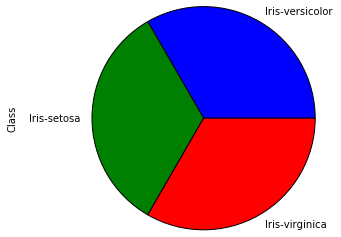
df['Class'].value_counts() Output:
Iris-versicolor 50
Iris-setosa 50
Iris-virginica 50
Name: Class, dtype: int64
Vemos que a base está bem distribuída, com a mesma quantidade de dados para todas as classes. Isso é um informação importante na hora de escolher o tipo de métrica (score) que usaremos para avaliar o resultado do nosso modelo. Podemos também plotar essa distribuição com o Matplotlib, para visualizar melhor os dados.
%matplotlib inline # Para os graficos aparecerem no jupyter
import matplotlib.pyplot as plt
df['Class'].value_counts().plot(kind='pie'); Output:
Criando features
A criação de features é um dos passos mais importantes do ML,
quanto melhor forem as features, mais facilmente o algoritmo irá achar padrões nos dados.
Uma forma de gerar features é aplicando matemática e estatística nos dados.
O Pandas é muito poderoso na manipulação dos dados, o que facilita muito a geração de novas features.
Ao fazer operações como *, + ou >, ele faz isso para cada linha da coluna e retorna uma nova coluna com os resultados:
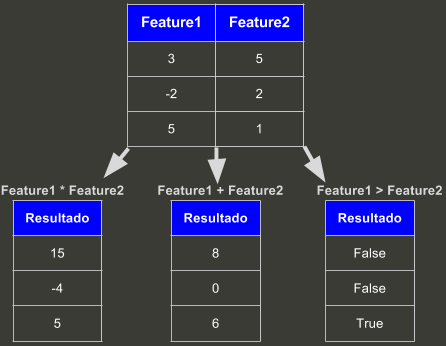
Também temos diversas funções no DataFrame que ao serem chamadas agem por toda a coluna, como .mean(), min(), mode() que irão retorna respectivamente média, valor mínimo e moda da coluna.
Vamos implementar algumas features:
# Como temos largura e comprimento, podemos criar uma feature de area
df['SepalArea'] = df['SepalLength'] * df['SepalWidth']
df['PetalArea'] = df['PetalLength'] * df['PetalWidth']
# Vamos tirar a media de cada feature e criar uma feature boleana
# que marca linha por linha se esses valores estao acima da media.
df['SepalLengthAboveMean'] = df['SepalLength'] > df['SepalLength'].mean()
df['SepalWidthAboveMean'] = df['SepalWidth'] > df['SepalWidth'].mean()
df['PetalLengthAboveMean'] = df['PetalLength'] > df['PetalLength'].mean()
df['PetalWidthAboveMean'] = df['PetalWidth'] > df['PetalWidth'].mean()Vamos ver os dados novamente, além das colunas que já vimos anteriormente, podemos ver também as novas colunas abaixo.
df.head() Output:
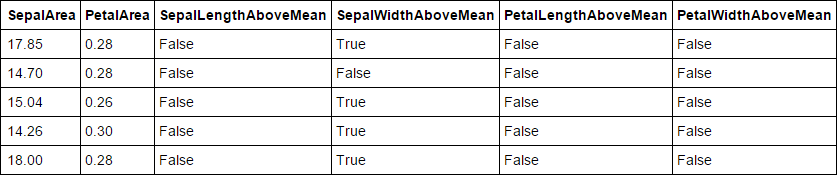
Além do Pandas, o Numpy e o próprio SkLearn possuem uma vasta quantidade de funções que podem ajudar na manipulação de dados e criação de features.
Com o Matplotlib também é possível plotar diferentes tipos de gráficos, que ajudar a entender melhor os dados e dar ideia para criação de features.
Recomendo dar uma olhada na documentação dessas bibliotecas e procurar exemplos de uso na internet para ter ideias e entender o que cada uma pode te oferecer.
Treinamento
Uma vez que possuímos um conjunto de entradas com suas features e as saídas, somos capazes de fazer o treinamento de um algoritmo, o treinamento basicamente vai passar por todas as entradas e achar um padrão que melhor descreve os dados e assim gerar um modelo capaz de prever a saída para novos dados.
Em nossa base de exemplo, todas as colunas são features, exceto a coluna Class que são as saídas. Caso queiramos ignorar alguma coluna que não serve como feature, como por exemplo, uma coluna de IDs, podemos apenas adicionar essa coluna na função .difference().
A variável features é uma lista com o nome das features. Ao passar uma lista para o DataFrame, isso serve como filtro, será retornado o DataFrame apenas com as colunas passadas no filtro. Por padrão, usamos X para os valores das entradas (features) e y para os valores das saídas.
features = df.columns.difference(['Class'])
X = df[features].values
y = df['Class'].valuesVamos pegar 3 exemplos de flores dos quais sabemos o resultado, para validarmos o modelo após o treinamento. Caso tenhamos gerado features extras para o modelo, precisamos gerar essas features também nas novas entradas.
# Iris-setosa
sample1 = [1.0, 2.0, 3.5, 1.0, 10.0, 3.5, False, False, False, False]
# Iris-versicolor
sample2 = [5.0, 3.5, 1.3, 0.2, 17.8, 0.2, False, True, False, False]
# Iris-virginica
sample3 = [7.9, 5.0, 2.0, 1.8, 19.7, 9.1, True, False, True, True]Existem diversos algoritmos de Machine Learning, nesse artigo vamos abordar dois algoritmos de classificação.
Decision Tree
Também conhecido como árvore de decisão, internamente é criada uma representação gráfica das alternativas disponíveis, similar a um fluxograma, com o objetivo de descobrir a classificação de uma nova entrada.
Um exemplo de uma árvore de decisão gerada a partir de um treinamento com o SkLearn, baseado nas features, é possível determinar qual é o tipo da flor. Essa árvore é gerada automaticamente quando efetuamos o treinamento.
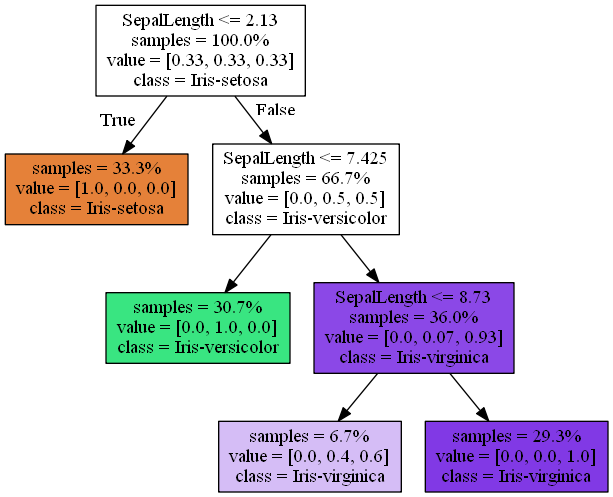
No SkLearn é bem simples fazer um treinamento usando esse tipo de algoritmo, basta criar o objeto e chamar o metodo .fit() passando os parâmetros X e y. Nesse momento o classificador vai ser ajustado para ser capaz de classificar qualquer conjunto de dados no mesmo formato.
from sklearn.tree import DecisionTreeClassifier
classifier_dt =
DecisionTreeClassifier(random_state=1986,
criterion='gini',
max_depth=3)
classifier_dt.fit(X, y)O objeto DecisionTreeClassifier possui diversos parâmetros:
random_state: É comum na maioria dos algoritmos e é importante mantê-lo fixo, o valor não importa, desde que seja sempre o mesmo, dessa forma conseguiremos gerar sempre o mesmo modelo com os mesmos dados.
criterion: É a métrica utilizada para construção da árvore de decisão. Pode ser gini ou entropy.
max_depth: É a profundida máxima da árvore, profundida demais pode gerar um sistema super especializado nos dados de treinamento, também conhecido como overfitting. Profundida de menos vai diminuir a capacidade de generalização do modelo.
Os parâmetros são mais detalhados na documentação e outros parâmetros também podem ser vistos.
Os melhores valores para cada um dos parâmetros, vária de acordo com os dados, com as features e até mesmo a mudança de um parâmetro pode influenciar no outro. Existem técnicas para procurar os melhores parâmetros, que serão abordadas mais a diante.
Uma vez que temos o modelo treinado, podemos tentar predizer a classificação dos exemplos que separamos posteriormente.
classifier_dt.predict([sample1, sample2, sample3])Output: array([‘Iris-setosa’, ‘Iris-versicolor’, ‘Iris-virginica’], dtype=object)
Vemos que o valor previsto condiz com a realidade, significa que nosso modelo é capaz de prever os dados como queríamos.
Validando Modelo
Temos uma base com 150 entradas, acertar apenas 3 não diz muita coisa, não somos capazes de determinar a eficiência do modelo apenas com isso.
Poderíamos testar com tudo? Isso iria mostrar que somos capazes de acertar os dados que usamos no treinamento. Podemos ser especialista nos dados que usamos no treinamento, mas não sermos capazes de acertar dados não usados. Isso é chamado de overfitting, é uma super especialização apenas nos dados de treinamento.
Podemos separar uma parte dos dados para o treinamento? É uma técnica bem comum, podemos separar 20%, 33% da base para ficar fora do treinamento e usarmos isso para validar o modelo depois, existe até a função train_test_split no SkLearn, que faz essa divisão dos dados mantendo inclusive a proporção das classificações. Porém essa abordagem tem um problema, como podemos garantir que escolhemos a parte certa? Que as entradas dela não são iguais da parte não escolhida? Ou que o padrão dos dados separados para teste, só existe neles, então o treinamento não teria a chance de treinar para pegar esse padrão?
Cross Validation
O Cross Validation serve para ajudar nessa validação do modelo.
A base será divida em várias partes, também chamado de folds, se dividirmos a base em 5 folds, usaremos 4 para treinar e 1 para validar. Mas diferente do formato anterior, não faremos isso apenas uma vez, mas 5 vezes, cada um dos folds será usado para validar enquanto treina com os outros 4, no fim a média desses 5 treinamentos é o resultado do modelo. Dessa forma garantimos que todos foram usados no treinamento e também que todos foram validados sem terem entrado no treinamento.
No exemplo abaixo, dividimos a base em 5 partes, treinamos com as partes verdes e validamos com a cinza, com isso teremos 5 resultados no final, a media deles é a métrica de eficiência do modelo.
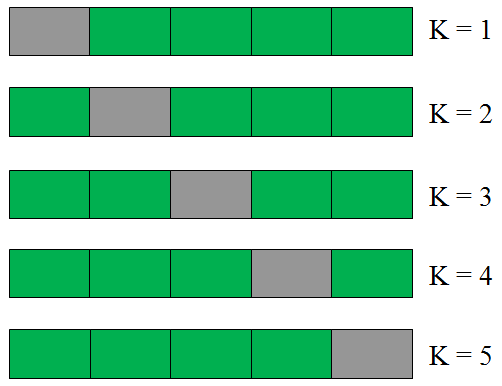
A implementação do Cross Validation é muito simples, com poucas linhas você já tem o resultado.
from sklearn.model_selection import cross_val_score
scores_dt = cross_val_score(classifier_dt, X, y,
scoring='accuracy', cv=5)
print(scores_dt.mean())Output: 0.953333333333
O método cross_val_score possui alguns parâmetros além do classificador e os dados de treinamento (X e y):
scoring: É a métrica utilizada para medir a eficiência do modelo, existem métrica especificas para os tipos de algoritmo, o que pode ser visto aqui. A métrica também pode variar de acordo com o objetivo, o tipo e o formato da base. No nosso caso, como temos um base balanceada, que possui exatamente as mesmas quantidades de entradas das 3 flores analisadas, podemos usar accuracy, caso fosse desbalanceada, poderíamos usar f1, roc_auc ou outros.
cv: E a quantidade de folds que será usada no Cross Validation.
Esse artigo explica muito bem as métricas mais populares: As Métricas Mais Populares para Avaliar Modelos de Machine Learning
Random Forest
O algoritmo Random Forest é um tipo de ensemble learning, método que gera muitos classificadores e combina o seu resultado.
No caso do Random Forest, ele gera vários decision trees, cada um com suas particularidades e combinada o resultado da classificação de todos eles. Essa combinação de modelos, torna ele um algoritmo muito mais poderoso do que o Decision Tree.
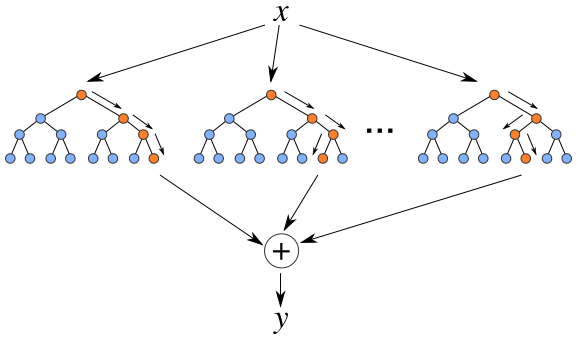
from sklearn.ensemble import RandomForestClassifier
classifier_rf =
RandomForestClassifier(random_state=1986,
criterion='gini',
max_depth=10,
n_estimators=50,
n_jobs=-1)
scores_rf = cross_val_score(classifier_rf, X, y,
scoring='accuracy', cv=5)
print(scores_rf.mean())Output: 0.96
Por ser um conjunto de Decision Trees, o objeto RandomForestClassifier possui diversos dos mesmos parâmetros, além de vários adicionais, entre eles temos:
n_estimators: É o número de estimadores (Decision Trees) que serão utilizados pelo Random Forest.
n_jobs: É o número de execuções em paralelo que serão usadas pelo seu modelo, ao passar -1, o valor será igual ao número de núcleos do computador executando. Quanto mais paralelizado for a execução, mais rápido será, desde que a máquina aguente. Diversas funções e objetos do SkLearn possui esse parâmetro.
max_features: É o número de features que será utilizado por cada Decision Tree interna, são sorteadas features diferentes para cada árvores, justamente para serem completamente diferentes.
Os scores de Decision Tree e Random Forest foram bem próximo no exemplo mostrado, isso é devido ao fato de a base utilizada ser bem simples, porém para base mais complexas, o Random Forest se sai muito melhor.
Feature Importance
Também podemos medir a importância de cada uma das features criadas, é algo legal, por que com isso podermos ver o que está dando certo, o que não está e ter ideias para novas features.
Antes de mandar imprimir a importância da features, devemos fazer um treinamento com a base completa.
classifier_rf.fit(X, y) # Treinando com tudo
features_importance = zip(classifier_rf.feature_importances_, features)
for importance, feature in sorted(features_importance, reverse=True):
print("%s: %f%%" % (feature, importance*100)) Output:
PetalArea: 31.614805%
PetalWidth: 29.375897%
PetalLength: 21.629776%
PetalLengthAboveMean: 7.188185%
SepalLength: 3.115694%
SepalArea: 2.513482%
SepalWidth: 1.804071%
PetalWidthAboveMean: 1.678833%
SepalLengthAboveMean: 0.853007%
SepalWidthAboveMean: 0.226249%
Grid Search
Vimos durante os exemplos que todos os algoritmos possuem diversos parâmetros. Os melhores valores para esses parâmetros mudam conforme os dados mudam, conforme você adiciona ou tira features e conforme muda os outros parâmetros também.
Mas então, como definir quais os melhores valores? Uma das técnicas que pode ser utilizada para isso é o Grid Search CV. Você passa para ele uma lista de possíveis valores e o score usado para medir a eficiência do modelo, ele vai rodar o Cross Validation com todas as possíveis combinações e no final vai te dizer qual a combinação apresentou o melhor score.
from sklearn.model_selection import GridSearchCV
param_grid = {
"criterion": ['entropy', 'gini'],
"n_estimators": [25, 50, 75],
"bootstrap": [False, True],
"max_depth": [3, 5, 10],
"max_features": ['auto', 0.1, 0.2, 0.3]
}
grid_search = GridSearchCV(classifier_rf, param_grid, scoring="accuracy")
grid_search.fit(X, y)
classifier_rf = grid_search.best_estimator_
grid_search.best_params_, grid_search.best_score_ Output:
0.973333333333
{‘max_depth’: 10, ‘bootstrap’: False, ‘max_features’: 0.1, ‘criterion’: ‘entropy’, ‘n_estimators’: 25}
Você não precisa rodar isso o tempo todo, uma vez que possua os melhores valores, apenas passe ele diretamente para o modelo. Somente depois de mudanças realmente significativas nos dados e nas features, será vantajoso rodar novamente, dependendo da base e da quantidade de combinações, pode levar horas ou até mesmo dias.
Com esse conhecimento inicial já é possível treinar um modelo e otimizar seu resultado. Caso algo não tenha ficado muito claro, por favor, deixe um comentário, que ficarei feliz em explicar.
O Jupyter notebook com todo o código pode ser visto aqui.
Voltar para página inicial: Carlos Baia